With the finale aired and a new Superstar crowned, I take some time to see how the algorithms perform overall, comparing predictions across all eight seasons. If you missed my earlier blog posts, see the first to understand what’s going on in the rest of this post.
The finale aired a couple weeks ago and we got our new Drag Race Superstar: Bob the Drag Queen!
The finale brought many great moments, including Carol Channing raving over Bob’s Snatch Game performance, Nancy Grace forcefully claiming Acid Betty was robbed in that same challenge, and Margaret Cho wishing Kim Chi luck. Speaking of Kim Chi, each of the top three performed a choreographed lip-sync to a song written specifically for them by Lucian Piane, and Kim Chi slayed despite not being able to dance.


Also, Violet Chachki reminded us why she deserved to win last season with her high fash-on!

Final Predictions
So how did the algorithms do overall? The table below contains final predictions. Overall, not too bad. Kim Chi and Bob were both predicted to come out on top, with only one algorithm each predicting 2nd instead of first. The best performing algorithm was the Gaussian Naive Bayes, with a rank score of 0.932!

| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Bob the Drag Queen | 1 | 8 | 1 | 1 | 1 | 2 | 1 |
| Kim Chi | 2 | 8 | 1 | 1 | 2 | 1 | 1 |
| Naomi Smalls | 3 | 8 | 1 | 3 | 7 | 6 | 3 |
| Chi Chi DeVayne | 4 | 8 | 5 | 4 | 3 | 4 | 5 |
| Derrick Barry | 5 | 8 | 4 | 4 | 4 | 3 | 4 |
| Thorgy Thor | 6 | 8 | 7 | 4 | 6 | 7 | 9 |
| Robbie Turner | 7 | 8 | 5 | 4 | 4 | 5 | 5 |
| Acid Betty | 8 | 8 | 8 | 9 | 9 | 8 | 9 |
| Naysha Lopez | 9 | 8 | 8 | 9 | 8 | 10 | 7 |
| Cynthia Lee Fontaine | 10 | 8 | 8 | 11 | 12 | 11 | 11 |
| Dax ExclamationPoint | 11 | 8 | 12 | 12 | 10 | 12 | 11 |
| Laila McQueen | 11 | 8 | 11 | 8 | 10 | 9 | 7 |
| Rank Score | 0.932 | 0.898 | 0.868 | 0.898 | 0.857 |
Predicting Other Seasons
Throughout the season I had been training the algorithms on data from seasons 1-6, testing on season 7, then predicting season 8. But I was curious how each algorithm would do at predicting all the other seasons. So I wrote a script that would step through each algorithm and season, training the algorithm on all the seasons other than the one it was predicting, and using this to predicting the relevant season. So for season one, all the algorithms have been trained on seasons 2-8, and then asked to predict season 1. I generated the following figure to plot the rank scores for each season for each algorithm.
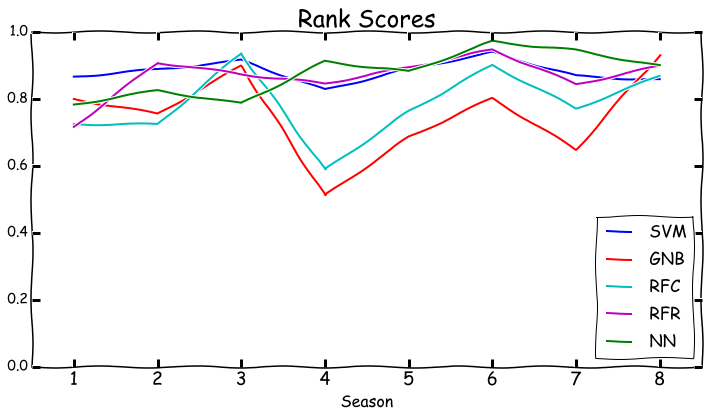
There’s a few interesting things going on here. Season 4 was especially tough to predict for Gaussian Naive Bayes and for the Random Forest Classifier. Season 7 was also a challenge for these algorithms. Support Vector Machines and Random Forest Regressor are both consistently good at predicting seasons, and Neural Network gets good past season 3. So what did each algorithm predict would happen in each season? Let’s find out.
Season 1
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Bebe Zahara Benet | 1 | 1 | 1 | 1 | 1 | 2 | 1 |
| Nina Flowers | 2 | 1 | 3 | 3 | 4 | 4 | 2 |
| Rebecca Glasscock | 3 | 1 | 4 | 4 | 3 | 3 | 4 |
| Shannel | 4 | 1 | 5 | 5 | 7 | 7 | 5 |
| Ongina | 5 | 1 | 1 | 1 | 1 | 1 | 2 |
| Jade | 6 | 1 | 6 | 7 | 6 | 6 | 7 |
| Akashia | 7 | 1 | 6 | 5 | 5 | 5 | 5 |
| Tammie Brown | 8 | 1 | 6 | 9 | 8 | 8 | 8 |
| Victora "Porkchop" Parker | 9 | 1 | 9 | 8 | 9 | 9 | 9 |
The algorithms all seemed to agree that BeBe Zahara Benet would come out on top, but they also predicted that Ongina would join her there. Ongina’s elimintation in season one was perhaps one of the hardest for RuPaul in all eight seasons, having to excuse herself from the set before she could decide who to send home.

Season 2
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Tyra Sanchez | 1 | 2 | 1 | 1 | 2 | 1 | 1 |
| Raven | 2 | 2 | 3 | 2 | 5 | 2 | 2 |
| Jujubee | 3 | 2 | 3 | 4 | 7 | 5 | 6 |
| Tatianna | 4 | 2 | 3 | 6 | 4 | 3 | 4 |
| Pandora Boxx | 5 | 2 | 3 | 4 | 1 | 8 | 5 |
| Jessica Wild | 6 | 2 | 2 | 7 | 2 | 4 | 2 |
| Sahara Davenport | 7 | 2 | 3 | 2 | 7 | 7 | 7 |
| Morgan McMichaels | 8 | 2 | 3 | 11 | 9 | 6 | 8 |
| Sonique | 9 | 2 | 10 | 8 | 6 | 10 | 8 |
| Mystique | 10 | 2 | 9 | 8 | 11 | 9 | 8 |
| Nicole Paige Brooks | 11 | 2 | 12 | 11 | 12 | 12 | 12 |
| Shangela-2 | 12 | 2 | 10 | 10 | 9 | 11 | 11 |
For season 2, the algorithms were pretty much in agreement about who would win. No other queens comes close to have the average ranking as Tyra Sanchez.

Season 3
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Raja | 1 | 3 | 1 | 4 | 1 | 2 | 2 |
| Manila Luzon | 2 | 3 | 1 | 1 | 1 | 1 | 1 |
| Alexis Mateo | 3 | 3 | 4 | 5 | 3 | 3 | 3 |
| Yara Sofia | 4 | 3 | 4 | 2 | 4 | 5 | 5 |
| Carmen Carrera | 5 | 3 | 6 | 7 | 6 | 7 | 7 |
| Shangela-3 | 6 | 3 | 3 | 5 | 5 | 4 | 3 |
| Delta Work | 7 | 3 | 8 | 9 | 7 | 10 | 8 |
| Stacy Layne Matthews | 8 | 3 | 8 | 2 | 7 | 6 | 8 |
| Mariah | 9 | 3 | 6 | 8 | 10 | 9 | 6 |
| India Ferrah | 10 | 3 | 11 | 10 | 13 | 13 | 10 |
| Mimi Imfurst | 11 | 3 | 8 | 10 | 9 | 8 | 11 |
| Phoenix | 12 | 3 | 11 | 10 | 11 | 12 | 11 |
| Venus D-Lite | 13 | 3 | 11 | 10 | 11 | 11 | 11 |
What’s really interesting in season 3 is that all five algorithms agreed that Manila Luzon would be taking home the crown, but she placed second after Raja. By the end of the season, Manila’s and Raja’s win/high/low/lipsync profile was identical, and so the three algorithms not placing Raja first must be dinging her on her age (Raja was 36 during the season, while Manila was 28). I’d also like to point out that favorite among my friends, Stacy Layne Mathews, was predicted to come in second by the Neural Network.

Season 4
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Sharon Needles | 1 | 4 | 1 | 1 | 2 | 1 | 1 |
| Chad Michaels | 2 | 4 | 1 | 2 | 1 | 2 | 3 |
| Phi Phi O'Hara | 3 | 4 | 1 | 4 | 2 | 3 | 2 |
| Latrice Royale | 4 | 4 | 9 | 4 | 4 | 4 | 3 |
| Kenya Michaels | 5 | 4 | 4 | 3 | 13 | 9 | 5 |
| DiDa Ritz | 6 | 4 | 12 | 8 | 8 | 10 | 5 |
| Willam | 7 | 4 | 5 | 7 | 7 | 5 | 9 |
| Jiggy Caliente | 8 | 4 | 10 | 4 | 5 | 8 | 5 |
| Milan | 9 | 4 | 5 | 10 | 5 | 7 | 5 |
| Madame LaQueer | 10 | 4 | 11 | 8 | 8 | 6 | 9 |
| The Princess | 11 | 4 | 5 | 10 | 8 | 11 | 13 |
| Lashauwn Beyond | 12 | 4 | 5 | 12 | 8 | 12 | 9 |
| Alisa Summers | 13 | 4 | 12 | 12 | 8 | 13 | 9 |
The algorithms in season 4 had a consensus that Sharon Needles would be taking home the crown, with Chad Michaels a close second (Chad won the first season of Drag Race All Stars shortly after season 4). Interestingly, even though Willam was eliminated at seventh place for violating the rules (her husband was making unauthorized conjugal visits to the hotel they were sequestered in), and so presumably would have made it further in the season, the algorithms predicted she would place approximately where she actually placed.

Season 5
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Jinkx Monsoon | 1 | 5 | 1 | 1 | 1 | 3 | 1 |
| Alaska | 2 | 5 | 1 | 2 | 2 | 1 | 3 |
| Roxxxy Andrews | 3 | 5 | 1 | 5 | 2 | 2 | 1 |
| Detox | 4 | 5 | 5 | 3 | 5 | 4 | 6 |
| Coco Montrese | 5 | 5 | 8 | 7 | 8 | 8 | 5 |
| Alyssa Edwards | 6 | 5 | 7 | 3 | 7 | 7 | 6 |
| Ivy Winters | 7 | 5 | 1 | 5 | 2 | 5 | 3 |
| Jade Jolie | 8 | 5 | 14 | 9 | 8 | 10 | 8 |
| Lineysha Sparx | 9 | 5 | 5 | 8 | 6 | 6 | 10 |
| Honey Mahogany | 10 | 5 | 10 | 14 | 14 | 13 | 11 |
| Vivienne Pinay | 11 | 5 | 10 | 9 | 8 | 9 | 8 |
| Monica Beverly Hillz | 12 | 5 | 10 | 11 | 12 | 11 | 11 |
| Serena ChaCha | 13 | 5 | 10 | 13 | 12 | 12 | 11 |
| Penny Traition | 14 | 5 | 9 | 11 | 8 | 14 | 11 |
Season 5 had the algorithms placing the top three in the right order, on average. What seems to have dragged the rank scores down for this season is how far Honey Mahogany made it – she was predicted to have gone home first by most of the algorithms. Coco Montrese seems to have made it further than predicted, possibly because the drama between her and Alyssa Edwards made such good TV (Also, Coco’s best moments were when she lip synced).

Season 6
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Bianca Del Rio | 1 | 6 | 1 | 1 | 1 | 1 | 1 |
| Adore Delano | 2 | 6 | 1 | 1 | 3 | 2 | 3 |
| Courtney Act | 3 | 6 | 1 | 3 | 1 | 3 | 1 |
| Darienne Lake | 4 | 6 | 7 | 4 | 4 | 5 | 4 |
| BenDeLaCreme | 5 | 6 | 1 | 4 | 5 | 4 | 4 |
| Joslyn Fox | 6 | 6 | 7 | 4 | 5 | 6 | 7 |
| Trinity K. Bonet | 7 | 6 | 9 | 7 | 5 | 8 | 8 |
| Laganja Estranja | 8 | 6 | 5 | 9 | 8 | 7 | 9 |
| Milk | 9 | 6 | 10 | 8 | 10 | 9 | 6 |
| Gia Gunn | 10 | 6 | 12 | 9 | 14 | 13 | 9 |
| April Carrion | 11 | 6 | 5 | 9 | 9 | 10 | 9 |
| Vivacious | 12 | 6 | 10 | 12 | 11 | 12 | 12 |
| Magnolia Crawford | 13 | 6 | 12 | 13 | 11 | 14 | 12 |
| Kelly Mantle | 14 | 6 | 14 | 14 | 11 | 11 | 12 |
Season 6 was easy to predict. It was pretty obvious from the first time Bianca Del Rio walked into the workroom she would taking home the crown. Each episode after merely confirmed the inevitable, and the algorithms agree. All five predicted Bianca to come in first.

Season 7
| Name | Place | Season | GNB | NN | RFC | RFR | SVC |
|---|---|---|---|---|---|---|---|
| Voilet Chachki | 1 | 7 | 1 | 1 | 3 | 1 | 1 |
| Ginger Minj | 2 | 7 | 8 | 1 | 1 | 2 | 2 |
| Pearl | 3 | 7 | 1 | 3 | 6 | 6 | 6 |
| Kennedy Davenport | 4 | 7 | 1 | 4 | 3 | 5 | 2 |
| Katya | 5 | 7 | 1 | 4 | 3 | 3 | 2 |
| Trixie Mattel | 6 | 7 | 8 | 7 | 8 | 7 | 6 |
| Miss Fame | 7 | 7 | 6 | 8 | 6 | 10 | 5 |
| Jaidynn Diore Fierce | 8 | 7 | 8 | 6 | 8 | 9 | 6 |
| Max | 9 | 7 | 1 | 9 | 1 | 3 | 9 |
| Kandy Ho | 10 | 7 | 6 | 10 | 11 | 8 | 10 |
| Mrs. Kasha Davis | 11 | 7 | 13 | 13 | 8 | 13 | 10 |
| Jasmine Masters | 12 | 7 | 11 | 10 | 13 | 11 | 10 |
| Sasha Belle | 13 | 7 | 11 | 10 | 11 | 12 | 10 |
| Tempest DuJour | 14 | 7 | 13 | 14 | 13 | 14 | 10 |
The algorithms had a difficult time deciding who would be in the top three in season 7. Max was predicted to be there by three algorithms, despite going home relatively early in the season. Four algorithms predicted Katya making it to the top three, while only two predicted Pearl getting so high. This actually tracks pretty well with what people were expecting early on in the season – Pearl was going to go home early, Max would make it pretty far, and Katya was going to make it to the top.

Overall, Support Vector Machine has the highest average rank score across all eight seasons, followed by Neural Network, Random Forest Regressor, Random Forest Classifier, and Gaussian Naive Bayes coming in last. Her performance in season 8 was largely a fluke compared to her performance the rest of the seasons.
This was a fun exercise for me. I learned more about how each of the machine learning algorithms worked, I practiced using python for data analysis, and I got to use a whole bunch of gifs of drag queens. You can find the code I used for both the weekly predictions, as well as the predictions in this blog post, on my github.